При запуске традиционного ПО в производство можно чётко предсказать поведение: пользователи следуют заданным маршрутам, а тесты охватывают 80–90% путей к коду. Мониторинг отслеживает частоту ошибок, время отклика и другие показатели. С агентами на базе LLM всё иначе — они обрабатывают ввод на естественном языке, и количество возможных запросов не ограничено. Поведение агентов недетерминировано: даже небольшие изменения во входных данных могут привести к разным результатам. Это связано с вероятностной выборкой при генерации и чувствительностью LLM к формулировкам, контексту и порядку инструкций.
Для мониторинга агентов нужны особые подходы. Необходимо фиксировать полные пары «запрос-ответ», многопользовательский контекст и каждый шаг в траектории действий агента, а не только итоговый ответ. Оценить качество взаимодействия часто можно только с помощью человеческого суждения: полезно ли сообщение, понял ли агент намерение пользователя, выбран ли подходящий тон и т. д. Но при тысячах или миллионах взаимодействий ручная проверка не масштабируется.
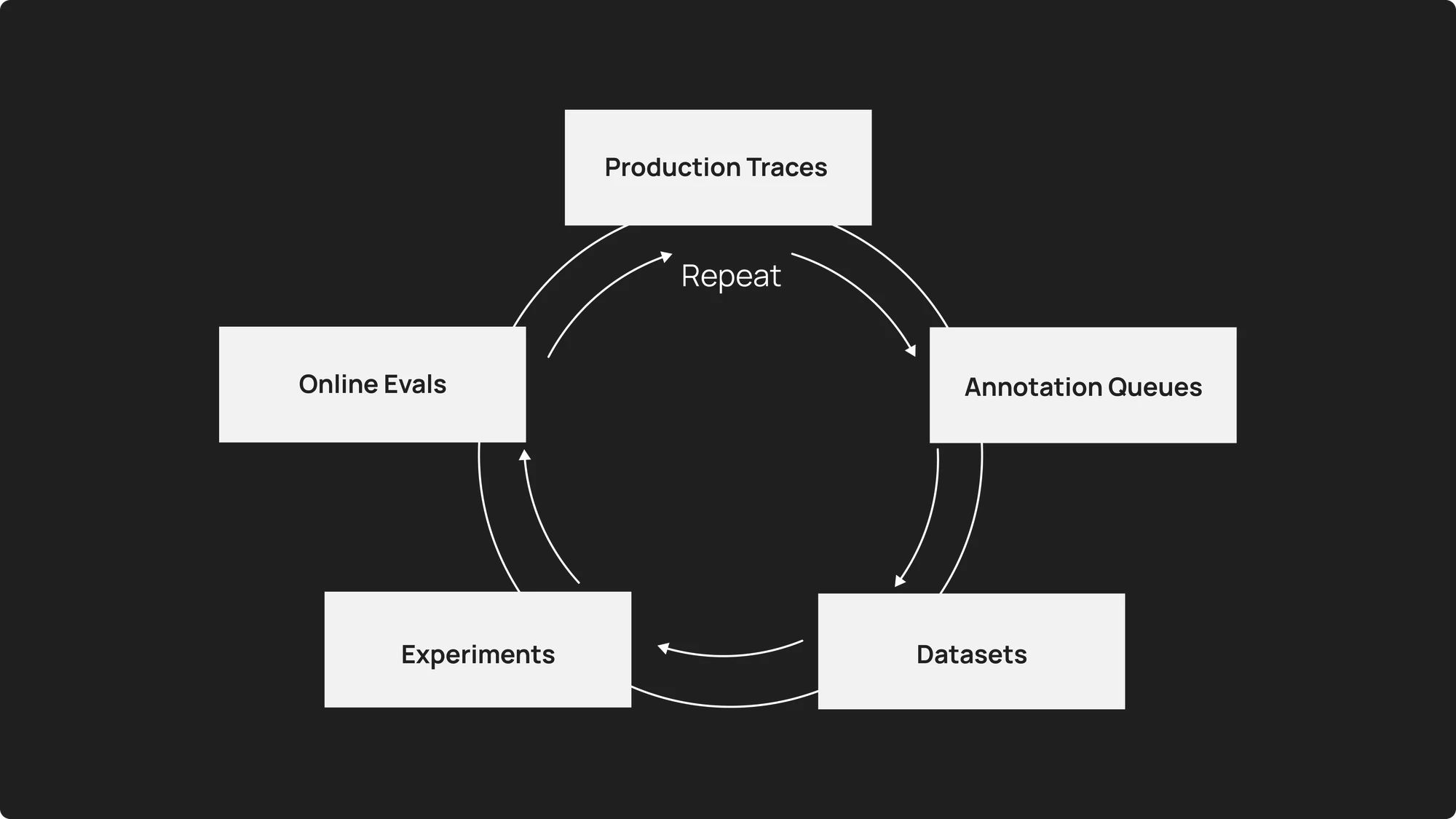
Авторы статьи предлагают два взаимодополняющих подхода. Первый — очереди аннотаций для структурированной проверки человеком. В них представлены конкретные прогоны в структурированном формате с предопределённой рубрикой. Система позволяет направлять на проверку определённые подмножества трассировок (например, прогоны с отрицательными отзывами), настраивать критерии проверки (релевантность, корректность, тональность, безопасность) и обеспечивать совместную работу команды.
Второй подход — использование LLM для оценки человеческого суждения. Онлайн-анализаторы могут автоматически запускаться на основе производственного трафика — либо для всех запусков, либо для выбранного подмножества. Они проверяют согласованность и тональность ответов, безопасность и соответствие требованиям, валидацию формата, тематическую классификацию запросов. Однако у такой оценки есть ограничения: например, она может добавлять несколько секунд задержки на трассировку. Рекомендуется сочетать автоматизированную оценку с периодической проверкой со стороны человека.
В LangSmith встроены инструменты для наблюдения за производственными агентами. Например, Insights Agent автоматически обнаруживает закономерности в использовании агента и ошибках. Он группирует похожие трассировки, чтобы выявить шаблоны использования, типы ошибок и крайние случаи. Его можно настроить для группировки трассировок по шаблонам использования, режимам сбоев или пользовательским атрибутам. Например, менеджер по продукту может узнать, для каких частей продукта пользователи чаще всего пытаются использовать copilot, а инженер — выяснить, почему агент выбирает неправильные инструменты.
Онлайн-оценки позволяют непрерывно отслеживать качество работы агента: можно настроить, какие трассировки оценивать (все, выборочные проценты или отфильтрованные подмножества), какие показатели проверять (качество, безопасность, валидация формата и др.), при каких условиях отправлять уведомления. С их помощью можно отслеживать, как часто агент выдаёт полезные и правильные ответы, автоматически классифицировать запросы по категориям, оценивать, выбрал ли агент подходящий путь к ответу, проверять наличие конфиденциальной информации в выходных данных в режиме реального времени.
Также важны информационные панели и оповещения. Настраиваемые панели позволяют отслеживать показатели успеха (например, выполнение задач или удовлетворённость пользователей) для разных рабочих процессов, сравнивать производительность в разных версиях модели, отслеживать затраты и задержку. Гибкое оповещение через webhooks или PagerDuty срабатывает, когда показатели превышают пороговые значения.
Традиционные инструменты APM (например, Datadog или New Relic) не вполне подходят для мониторинга агентов. Они оптимизированы для работы со структурированными журналами и числовыми показателями, а для агентов нужны возможности семантического поиска по запросам, особые структуры данных для поддержания потоков сообщений и состояния, тесная интеграция между платформой наблюдения, платформой оценки и инструментами разработки. LangSmith обеспечивает такую интеграцию: можно щёлкнуть по сбойной производственной трассировке, добавить её в набор данных, изменить запрос в среде playground, провести эксперимент по сравнению старой и новой версий и выполнить повторное развёртывание.
Наблюдаемость агентов важна для межфункциональных команд: инженеров по AI/ML, менеджеров по продуктам, экспертов по предметной области, специалистов по обработке данных. Они анализируют производственные данные, обсуждают закономерности и принимают решения о приоритетах.
Среди открытых задач — точность и надёжность оценщиков, затраты в зависимости от масштаба мониторинга, вопросы конфиденциальности и соответствия требованиям. Описанные подходы (структурированные очереди аннотаций, автоматическое обнаружение шаблонов, непрерывная оценка) отражают современное видение того, как сделать поведение производственных агентов наблюдаемым и улучшаемым в масштабе.

