

ИИ

Машинное обучение

Стабильная диффузия

AIidea (генерация изображений с помощью диффузионных моделей)
Оригинальный текст: https://arxiv.org/abs/2601.22125
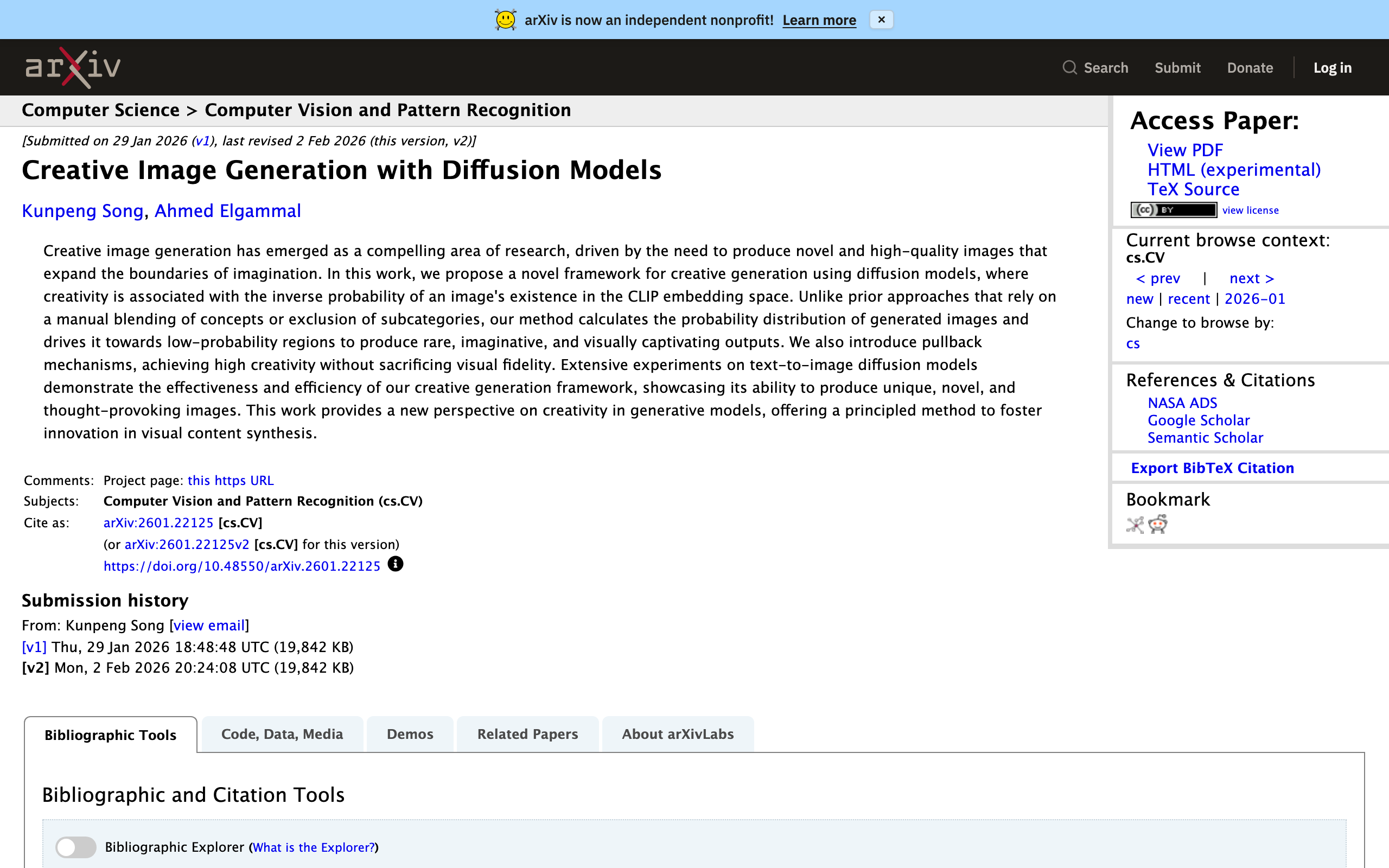
Источник: Кунпенг Сонг, Ахмед Эльгаммаль / arXiv (https://arxiv.org/abs/2601.22125). Лицензия: CC BY 4.0.
Эта статья представляет собой полный перевод публикации, размещённой под лицензией CC BY 4.0. Номер заголовка сохранён в соответствии с оригинальной структурой. Исходные символы формул оставлены без изменений, а первый жаргонный текст дополнен японским (). Все добавления переводчика явно обозначены как «(訳注)». Рисунок приведён в соответствии с оригиналом (arXiv).
Рисунок: изображение этого метода. Продукт КЛИП перемещается из центра гауссова распределения встроенного пространства (высокая вероятность — распространённый вариант) в конец (низкая вероятность — креативный вариант) (графическая схема, созданная переводчиком).
Аннотация (Abstract)
Генерация креативных изображений стала перспективным направлением исследований — это обусловлено потребностью создавать новые высококачественные изображения, которые расширяют границы воображения. В рамках данного исследования мы предлагаем новую концепцию креативной генерации с использованием диффузионных моделей (моделей, которые создают изображения, устраняя шум). Здесь креативность связывается с вероятностью, обратной вероятности существования изображения в пространстве встраивания клипа (пространстве, где изображения и текст представлены единым числовым вектором). В отличие от традиционных методов, предполагающих ручное смешивание концепций или исключение подкатегорий, наш метод рассчитывает распределение вероятностей сгенерированных изображений и распределяет их по областям с низкой вероятностью — это позволяет получать редкие, оригинальные и визуально привлекательные результаты. Кроме того, мы внедряем механизм возврата, который обеспечивает высокую креативность без потери визуальной точности. Масштабные эксперименты с моделью преобразования текста в изображение подтверждают эффективность этого подхода: он способен генерировать уникальные, новаторские и наводящие на размышления изображения. Исследование открывает новый взгляд на креативность в генеративных моделях и предлагает принципиальный подход к стимулированию инноваций в создании визуального контента.
(Страница проекта: https://creative-t2i.github.io/)
- Введение (Introduction)
Рисунок 1: творческое создание зданий и транспортных средств с помощью этого метода — на это требуется всего 2 минуты.
С появлением моделей, создающих изображения из текста (таких как Stable Diffusion, SDXL и DALL), у нас появился уникальный инструмент для преобразования текста в разнообразные высококачественные изображения. Благодаря этим разработкам стало возможным широкое применение технологий — от создания изображений по текстовому описанию до их редактирования. Современные технологии персонализации ещё больше расширили возможности настройки и адаптации процесса создания изображений.
Креативность остаётся одним из ключевых признаков человечности. Она связана с редкостью и неожиданностью, опирается на единство восприятия, которое разделяют создатель и наблюдатель. В связи с этим возникает важный вопрос: способны ли современные мощные ИИ-системы генерировать по‑настоящему новые и креативные результаты? Иными словами, могут ли модели ИИ быть по‑настоящему креативными?
Мы утверждаем, что эти системы в корне лишены креативности, и на то есть соответствующие причины. Они разработаны так, чтобы имитировать распределение обучающих данных, а функция потерь (показатель того, насколько хорошо или плохо идёт обучение) заметно смещена в сторону типичного результата. Кроме того, при оценке стандартные показатели обычно определяют, насколько сгенерированное изображение близко к обучающим данным — это непреднамеренно способствует антикреативной предвзятости (то есть предвзятости, которая отдаёт предпочтение тиражированию, а не инновациям). По сути, модели генерации изображений в основном нацелены на улучшение качества изображения. Это пример компромисса между качеством и креативностью (взаимосвязь, которую трудно сбалансировать), причём приоритет отдаётся качеству изображения — оно следует распределению обучающих данных. Эти модели искусственного интеллекта сильно ориентированы на типичные, а потому по сути скучные результаты. Пользователи часто опираются на человеческий вклад как на источник креативности и используют оперативное проектирование, чтобы получать от системы новые и уникальные результаты — так они заимствуют человеческий творческий потенциал.
В этой статье мы представляем систему искусственного интеллекта нового поколения, которая способна генерировать новые изображения. Мы работаем над задачей создания креативного текста → изображения, где креативность определяется как «способность создавать новые высококачественные продукты с низкой вероятностью существования». В отличие от методов, которые явно смешивают и комбинируют концепции, наш метод использует выборки из областей выходного пространства сгенерированной модели с низкой вероятностью и способствует творческому подходу без ручного вмешательства. Например, в категории «сумки» мы стремимся создавать изображения, которые семантически похожи на сумки, но отличаются от известных общепринятых норм. Эта стохастическая структура обеспечивает эффективный подход к креативности: она расширяет границы генеративных моделей и открывает новые возможности для создания творческого визуального контента. Ниже приведены конкретные вклады.
Новый взгляд на креативный искусственный интеллект. Мы рассматриваем создание креативных изображений через призму вероятности и целенаправленно работаем с областью с низкой вероятностью — это позволяет стимулировать появление новых результатов.
Оптимизация ориентации на креативность. Мы разработали специальную функцию потерь, которая напрямую стимулирует поиск изображений для встраивания с меньшей вероятностью — благодаря этому модель выдаёт более креативные результаты.
Управление откатом и направлением. Мы ввели ограничение на откат, чтобы предотвратить выход за пределы ожидаемого диапазона. Кроме того, мы представляем метод, который позволяет направлять траекторию поиска модели в определённом направлении — при этом сохраняются и креативность, и семантическая точность.
2 Работы по теме
2.1 Противодействие креативности в генеративных системах
Модели генерации изображений нацелены на создание изображений, похожих на обучающие данные, и часто не имеют механизма для изучения творческих пространств. Обычная сеть GAN (hostile generation network) использует выборку из распределённых данных, но в ней нарушается баланс между качеством и разнообразием, что приводит к таким проблемам, как сбой режима (явление, при котором некоторые режимы теряются). Чтобы решить эту проблему, такие методы, как усечение Биггана (truncation of latent vectors), корректируют скрытые векторы так, чтобы качество было важнее разнообразия. Другие генерирующие модели, в том числе вариационные автокодеры (VAE), потоковые методы и модели подбора баллов, тоже скорее копируют распределение обучения, чем способствуют творчеству. Используя выборки VAE из изученного скрытого пространства, потоковая модель преобразует эталонное распределение, а сопоставление результатов оценивает градиент данных. Диффузионные модели улучшают формирование изображений за счёт снижения уровня шума и часто повышают качество, направляя методы с помощью текстовых подсказок. Однако, как и другие методы, они оптимизированы для восстановления изображений и не мотивируют к исследованиям за пределами обучающих данных.
2.2 В оценочных метриках используется предвзятое отношение к креативности
Стандартные показатели, которые оценивают созданные системы искусственного интеллекта, отдают приоритет качеству изображений, а не креативности. FID (начальное расстояние Фреше) — широко используемый показатель в этом контексте для измерения сходства между распределением реальных и сгенерированных изображений. FID — это показатель «типичности», отдающий предпочтение обычным изображениям. Системы с более высокими показателями FID с меньшей вероятностью дадут инновационные результаты. Другой показатель, IS (Inception Score), оценивает систему создания изображений на основе качества и разнообразия. Хотя IS гарантирует полноту между подкатегориями, он не способствует новизне как внутри, так и за пределами подкатегорий.
2.3 Связанная с этим работа над креативными системами создания изображений
До появления современного генеративного ИИ в литературе по вычислительной креативности предлагались алгоритмы для эффективного изучения креативных пространств. Многие из них используют эволюционные процессы: генерируют кандидатов, оценивают их с помощью функций приспособленности и улучшают для следующей итерации — часто в рамках генетических алгоритмов. Задача заключалась в том, как спроектировать логическую фитнес‑функцию с учётом эстетики. Некоторые системы включали обратную связь с человеком, что побуждало людей к творческим исследованиям. В последние годы система подчёркивает важность восприятия и познания в творчестве.
В контексте GAN мы показываем, что CAN (творческие состязательные сети) могут компенсировать потери GAN, поощряя творческий поиск. Это создало напряжённость между соблюдением общих правил распространения произведений искусства и созданием уникального и новаторского художественного стиля. Эта напряжённость подтолкнула систему к созданию нового продукта, в котором достигнут баланс между новизной и ценностью. В области распространения текста → изображений недавно была представлена ConceptLab, которая позволяет внедрить в систему новые концепции и стили. Устанавливая такие ограничения для подсказок, как «Создавать изображения домашних животных, которые не являются кошками, собаками или хомяками», система косвенно подталкивает к творчеству. И CAN, и ConceptLab используют преимущества существования подкатегорий в рамках общей концепции и подталкивают систему к созданию новых изображений, которые относятся к концепции, но не относятся к подкатегории. В отличие от этого предлагаемый нами метод отличается тем, что не предполагает и не зависит от существования таких подкатегорий и направлен непосредственно на оптимизацию творческих потерь.
2.4 Генеративные модели, основанные на диффузии
Крупномасштабные модели преобразования текста в изображение открыли беспрецедентные возможности для создания высококачественных изображений по текстовым подсказкам. Во многих исследованиях предпринимались попытки использовать эти мощные модели для последующего редактирования. Большинство методов генерации вводного текста напрямую зависят от данных, извлечённых из предварительно обученных текстовых кодеров. В этом исследовании мы используем Kandinsky 2.1 — модель скрытой диффузии, которая включает предшествующую и последующую диффузию.
- Мотивация и обоснование
Справочная информация: в психологической литературе Д. Э. Берлинне (1924–1976) подчёркивал роль «возбуждения» в эстетике. Возбуждение — это показатель настороженности, который варьируется от расслабленного состояния до сильного возбуждения. Потенциал возбуждения связан с природой стимуляции, усиливающей возбуждение. Наиболее важными факторами для эстетики являются новизна, неожиданность, сложность, двусмысленность и непостижимость. Он назвал эти переменные совокупными. Исследования показали, что предпочтителен умеренный потенциал возбуждения: если он слишком низкий, возникает скука, а если слишком высокий — активируется отвращение и снижается реакция удовольствия. Эта зависимость описывается кривой Вундта, однако была предложена и альтернативная модель.
Новизна и неожиданность: новизна в креативной генерации — это не просто создание невиданного образца. В многомерном пространстве, которое используют модели GAN и диффузии, образцы, близкие к среднему значению, часто бывают новыми, но типичными. Креативность требует отклонения от среднего значения, чтобы увеличить потенциал возбуждения. Креативные системы должны находить баланс между новизной и ценностью. Увеличение новизны предполагает отбор образцов из областей с низкой вероятностью, однако чрезмерные отклонения снижают воспринимаемое качество. Поэтому для корректировки новизны без ущерба для её ценности понадобится механизм «отката назад».
Увеличение потенциала возбуждения в образце: модели Берлине связывают новизну с отклонениями от прошлого опыта. Мы сосредоточимся на новизне как на факторе, который повышает креативность.
В среде моделирования новизну можно количественно оценить с помощью теории информации с учётом прошлого опыта пользователя. Поскольку прямые измерения нереалистичны, мы аппроксимируем экспозицию путём выборки изображений, связанных с запросом пользователя, и строим модель M. Затем потенциал возбуждения (AP) оценивается следующим образом:
AP_{новизна}(x|M)=-\log(P(x|M))
С точки зрения теории информации новизна совпадает с неожиданностью. В этой статье мы считаем эти понятия эквивалентными, поскольку статистические ожидания позволяют определять неожиданности на основе данных обучения.
- Предварительная (подготовительная)
Модель скрытой диффузии. Модель скрытой диффузии (LDM) создаёт изображение, выполняя процесс диффузии в сжатом скрытом пространстве. Формально пусть x\in\mathbb{R}^{H\умножить на W\умножить на 3} — изображение, а \mathcal {E} и \mathcal{D} — кодеры и декодеры автокодеров соответственно. Кодер \mathcal{E} преобразует x в скрытое представление z=\mathcal{E} (x), а декодер \mathcal{D} восстанавливает его так, что \mathcal {D}(z) приблизительно соответствует X.
Модель диффузии обучается на скрытом коде {z} с использованием целевой функции DDPM. Пусть z{t} — скрытый код на временном шаге t диффузии. Сеть \epsilon{\theta} учится предсказывать вводимый шум \epsilon на каждом шаге — в зависимости от скрытого кода z_{t}, временного шага t и любого вектора условий C.
\mathcal{L}{\text{LDM}}=\mathbb{E}{z,\epsilon,t}\bigl[|\epsilon-\epsilon{\theta}(z{t},t,c)|^{2}\bigr] \четырехъядерный (1)
Предварительное распределение изображений по тексту → диффузия. Наш метод основан на Kandinsky 2.1, который разбивает создание текста → изображения на два этапа: (i) диффузионное предварительное распределение \epsilon{\theta}, которое предсказывает встраивание изображения клипа e\in\mathbb {R}^{m} из текстового запроса, и (ii) диффузионный декодер, который принимает встраивание изображения и генерирует изображение. Формально диффузионное предварительное распределение \epsilon{\theta} обучается с помощью:
\mathcal{L}{\text{prior}}=\mathbb{E}{e,\epsilon,t}\bigl[|\epsilon-\epsilon{\theta}(e{t},t,\phi(P))|^{2}\bigr] \quad (2)
, где P — текстовое приглашение, \phi — кодер текста, а e_{t} — встраивание изображения с добавлением шума. С помощью этого двухэтапного подхода можно гибко управлять внедрением промежуточных изображений из клипов.
5 Метод
Рисунок 2: общая структура модели. Сначала рассмотрим распределение (зелёный кластер) встроенного изображения e, сгенерированного из предварительного распределения diffusion \epsilon_{\theta} (вверху). Далее в creative optimization (внизу) creative loss используется для оптимизации обучающего токена и слоя LoRa, а сгенерированное встраивание (красная точка) отображается и перемещается в область с низкой вероятностью (оранжевая стрелка). Этот поиск ограничен потерей привязки и проверяется с помощью multimodal LLM. Наконец, декодер diffusion отображает результирующее изображение.
Здесь подробно описан дизайн модели для создания креативного текста → изображения. Система создания креатива состоит из четырёх компонентов: 1) концептуальное пространство, 2) критерии оптимизации, 3) механизм отката, 4) направление. На высоком уровне (см. рис. 2) мы сначала изучаем базовое распределение e для встраивания изображений из предварительного распределения diffusion \epsilon_{\theta} (5.1). Затем мы рекомендуем провести поиск области распределения с низкой вероятностью (5.2). Сочетание этих факторов увеличивает возможность получения новых, «креативных» результатов. Далее в версии 5.3 применяются ограничения на откат, включая положительные привязки и средство проверки семантической достоверности MLLM, для обеспечения семантической достоверности и эффективного предотвращения сбоев, связанных с доменом. Наконец, в 5.4 мы вводим управление направлением с помощью отрицательных кластеров. Далее каждый элемент будет подробно описан.
5.1 Предварительная выборка распределения
Как упоминалось в разделе 4, e\in\mathbb {R}^{m} представляет собой встраивание изображения, которое создаёт предварительное распределение diffusion \epsilon{\theta} при получении текстового запроса P. Мы рисуем большое количество образцов {e{i}}{i=1}^{N} и аппроксимируем базовое распределение вложения сгенерированного изображения, вызванное предыдущим распределением \epsilon{\theta}. Применяем анализ главных компонент (PCA), чтобы уменьшить размерность и получить \tilde {e}\in\mathbb {R} ^{k}(k\ll m). Затем сопоставляем многомерное гауссово распределение \hat {G}(\tilde {e}) с выборкой после этого преобразования PCA. Формально это выглядит следующим образом:
\тильда{e}=\mathbf{W}(e-\mathbf{\mu{0}}) \квадрат (3)
\hat{G}(\tilde{e})=\mathcal{N}\bigl(\tilde{e}\mid\mathbf{0},\mathbf {\Sigma}\bigr) \quad (4)
, где \mathbf {W} — проекционная матрица PCA, \mathbf{\mu{0}} — среднее значение исходного вложения, а \mathbf{\Sigma} — предполагаемая ковариация в пространстве редукции.
5.2 Творческая оптимизация
Концептуальное пространство. Концептуальное пространство — это пространство параметров, которые креативные системы исследуют в процессе оптимизации. В качестве концептуального пространства для творческого исследования мы используем пространство, сочетающее параметры внедрения токенов и LoRa (адаптация низкого ранга). В частности, оно оптимизирует как внедрение токенов (например, транспортных средств), так и матрицу ранговой декомпозиции LoRa для предварительного распространения diffusion \epsilon_{\theta}.
Используйте P{pos} в качестве положительной подсказки (например, «фотография транспортного средства»). Примерами подсказок, используемых на практике, являются: «Профессиональная высококачественная фотография транспортного средства, фотореалистичная, 4k, HQ». P{opt} используется в качестве подсказки, содержащей токен, который нужно оптимизировать (например, «фотография <токена>»). Это внедрение обученного токена инициализируется с помощью тематического токена по умолчанию (например, «транспортное средство»). Для параметра LoRa все матрицы A инициализируются случайным образом, а все матрицы B равны нулю.
Творческая потеря. Мы работаем над созданием креативных образов, повышая их привлекательность (см. раздел 3). Основная идея заключается в том, что для создания креативного образа необходимо отойти от сферы внедрения с высокой вероятностью. С этой целью мы определяем функцию креативных потерь, которая поощряет вложение предсказания в \tilde{e} после уменьшения размерности оставаться в области меньшей вероятности в \hat{G}. В частности, логарифмическая вероятность минимизируется.
\mathcal{L}_{\text{creative}}(\tilde{e})=\log\hat{G}(\tilde{e}) \quad (5)
\mathcal{L}_{\text{creative}} помещает \tilde {e} в конец распределения \hat{G}, увеличивая вероятность получения нового креативного образца.
5.3 Механизм отката. Как отмечалось в разделе 3, ограничение потенциала возбуждения важно для предотвращения сбоев в работе вне домена. Слишком большое отклонение модели от её первоначального распределения может привести к ухудшению качества и семантической достоверности. Чтобы смягчить это, мы вводим два механизма отката, которые ограничивают генерируемый результат в соответствии с предполагаемой концепцией: потеря привязки и проверка MLLM.
Потеря привязки. Чтобы предотвратить чрезмерное отклонение модели от творческой оптимизации, мы используем потерю привязки на основе клипов. Это косинусное сходство между сгенерированным вложением изображения e и вложением текста P_{pos}. Формально это выглядит следующим образом:
\mathcal{L}{\text{anchor}}=1-\frac{\langlee,\phi(P{pos})\rangle}{|e|,|\phi(P_{pos})|} \quad (6)
Здесь \phi представляет собой кодировщик текста. Потеря привязки гарантирует, что сгенерированное изображение останется семантически согласованным с темой, описанной в P_{pos}, даже если вы переместите его в область с низкой вероятностью (и, возможно, более креативную).
Проверка семантической достоверности. Чтобы компенсировать потерю привязки, используется мультимодальная крупномасштабная языковая модель (MLLM) для периодической проверки семантической согласованности выходных данных. Для каждых нескольких итераций оптимизации мы генерируем изображение, встраиваемое в e, из оптимизированного diffusion pre-distribution \epsilon_{\theta}, и визуализируем фактическое изображение с помощью diffusion decoder. И «Это всё ещё {объект}? Да или нет» («Это всё ещё {тема}? Да или нет»), — спрашивает MLLM. Если MLLM подтверждает, что сгенерированное изображение соответствует задуманной концепции, оптимизация продолжается, в противном случае попытка завершается. Этот механизм действует как внешняя семантическая контрольная точка, гарантируя, что творческий процесс не приведёт к созданию «чего‑либо, имеющего смысл» за пределами предметной области. В разделе 7.5.4 показано, что MLLM по‑прежнему важен даже при действительной потере привязки.
Эти два механизма позволяют сбалансировать стремление к креативности и необходимость сохранения качества и семантической точности создаваемых изображений.
5.4 Направленность
Мотивация. Механизмы творческой потери и отката гарантируют, что созданные изображения будут редкими и семантически будут соответствовать задуманной концепции, но не гарантируют, что их результат будет привлекательным или интересным для людей. Поскольку процесс оптимизации является стохастическим по своей природе, он может привести модель к определённым областям, которые отвечают этим критериям, но неизменно дают непривлекательные и нежелательные результаты. Для решения этой проблемы мы предлагаем управление направлением с помощью моделирования отрицательных кластеров.
Моделирование отрицательных кластеров. Если наблюдается, что внедрение одного токена приводит к постоянному нежелательному результату, это приводит к внедрению негативного изображения {\тильда BOSe}{neg\sim j}}{j=1}^{N}. Как и в разделе 5.1, спроецируйте эти вложения в то же пространство сокращения PCA и установите отрицательное многомерное гауссово распределение \hat {G}{\text{neg}}(\tilde{e{neg}}). Это распределение отражает «неблагоприятные кластеры», которых мы хотим избежать. В последующих испытаниях мы отбираем новый образец из этой неблагоприятной области, добавляя штрафной срок к творческим потерям.
\mathcal{L}{\text{neg}}(\tilde{e})=-\alpha\log\hat{G}{\text{neg}}(\tilde{e}) \quad (7)
, где \alpha — скаляр интенсивности. Общие потери составили бы:
\mathcal{L}=\mathcal{L}{\text{creative}}(\tilde{e})+\mathcal{L}{\text{neg}}(\tilde{e})+\mathcal{L}{\text{anchor}} \четырехъядерный (8)
Это приводит к нарушению согласования с негативным кластером \hat{G}{\text{neg}}(\tilde{e}). Результирующая модель ориентирована на поиск альтернативных творческих направлений, не ограничиваясь областями, которые, как известно, приводят к нежелательным результатам.
6 Деталей реализации
Мы используем официальную реализацию модели Kandinsky 2.1 Text→Image, а в подсказке для ввода используется расширенный текстовый кодер, рекомендованный ConceptLab. На этапе предварительной выборки для распространения 5000 вставок изображений из предварительного распространения diffusion генерируются с использованием P_{pos} на этапе распространения 5‑размер пакета 500. Этот процесс завершается менее чем за 1 минуту. Результирующее вложение изначально находится в \mathbb {R} ^ {768}, но с помощью PCA оно уменьшено до k = 50 измерений, чтобы охватить большую часть общей дисперсии.
На этапе творческой оптимизации тренируйтесь на одном графическом процессоре NVIDIA A100, выполняя до 1000 шагов, размер пакета 1. Как для внедрения токенов, так и для уровня LoRa (ранг = 10) AdamW использует фиксированную скорость обучения, равную 1 × 10^{−4}. Кроме того, каждые 25 итераций он запрашивает один из многомодальных LLM от DeepSeek‑AI Janus‑1.3B или LLaVA‑Next для выполнения семантической проверки достоверности и автоматически останавливает попытки, если обнаруживаются результаты, не относящиеся к домену. Как показывает опыт, творческие и визуально интересные результаты начинают проявляться уже после первых 50 шагов, менее чем через 2 минуты после начала.
7 Экспериментов
7.1 Визуальные результаты
Наш метод позволил создать очень креативные и интересные изображения. На рисунке 1 показаны визуальные результаты по 4 темам: здание, транспортное средство, инопланетянин и фрукты. Эти примеры показывают, что метод может генерировать чрезвычайно новые и визуально интересные результаты по различным категориям. Более наглядные результаты приведены в приложении.
7.2 Эволюция сгенерированного распределения
Чтобы ещё раз проверить этот метод, на рисунке 3 показано, как изменяется распределение сгенерированного изображения при внедрении e в процессе обучения. По мере оптимизации распределение e постепенно приближается к границе и попадает в область с меньшей вероятностью. Соответственно, генерируемые изображения со временем становятся всё более креативными. Это подтверждает, что метод эффективен для продвижения модели в новую область, и демонстрирует чёткую корреляцию между сдвигом распределения в конец и креативностью результатов.
Рисунок 3: Визуализация изменения распределения e на итерациях обучения. Зелёный кластер — это распределение по умолчанию для предыдущего этапа выборки распределения (раздел 5.1), а красный кластер — текущее распределение. Сгенерированное изображение постепенно перемещается в область с низкой вероятностью и со временем становится более креативным.
7.3 Оценка человеком потенциала возбуждения
В разделе 3 мы описываем кривую Вундта — соотношение между потенциалом возбуждения, креативностью и вероятностью. В этом эксперименте мы проводим испытание на субъекте alien (чужой), чтобы проверить эту концепцию. Для этого механизм отката временно отключают и проводят испытания с 5 различными обучающими семенами. Креативность созданных изображений оценивали люди по шкале от 0 до 5 (подробности в приложении). Полученные результаты (см. рисунок 4) демонстрируют чёткую закономерность: оценка креативности постепенно повышается — от скучной до интересной (около 3) и очень интересной (около 4), а затем в итоге падает до 0, когда модель выходит за пределы оптимального диапазона возбуждения (overshoot). В качестве примера изображения для опроса используют выходные данные по умолчанию, а оценка креативности в этом случае равна 1 (скучно), где 0 баллов означает, что изображение не относится к предметной области (см. рис. 2). Эта траектория соответствует ожидаемой кривой потенциального возбуждения, подтверждая теоретическую основу и доказывая, что метод может эффективно исследовать эту кривую.
Рисунок 4: Оценка креативности пользователями в ходе итераций обучения по теме «чужой». Наблюдаемая закономерность повторяет кривую потенциального возбуждения, демонстрируя, как метод (аннулирование результатов) сначала эффективно повышает креативность, а затем переходит все границы.
Рисунок 5: Креативно созданные изображения здания и стула.
7.4 Сравнение с исходным уровнем
7.4.1 Качество и скорость (Качество и скорость)
На рисунке 5 показано сравнение предложенного метода с ConceptLab для тематических зданий и стульев. Хотя этот метод позволяет создавать гораздо более креативные и концептуально насыщенные образцы, исходные изображения, как правило, получаются слишком банальными или лишены творческого выражения в желаемом смысле. Эти качественные наблюдения дополнительно подтверждаются количественной оценкой человека, приведённой в разделе 7.4.2.
Чтобы проверить скорость и эффективность этого метода, мы сравниваем, как изменяются сгенерированные изображения в процессе обучения для исследуемого транспортного средства. На рисунке 6 левая панель представляет выходные данные ConceptLab, а образец креатива появляется после 300 итераций. ConceptLab достигает креативности, избегая подклассов: сначала создаёт результаты, относящиеся к конкретной подкатегории (например, джипы, автобусы), а затем переходит к более креативным результатам. С другой стороны, наш метод, который работает непосредственно с распределением и вероятностным пространством, с самого начала даёт творческий результат. Такая скорость сходимости не только подчёркивает эффективность метода, но и соответствует нашей интуиции. Иными словами, манипулируя распределением, больше нет необходимости явно исключать подкатегории — можно быстрее находить новые области встроенного пространства с низкой вероятностью.
Рисунок 6: сравнение создания креативного транспортного средства на разных итерациях (50, 150, 300, 500). ConceptLab (слева) постепенно изучает подкатегории, прежде чем перейти к креативному дизайну. Этот метод (справа) не только быстрее, но и значительно креативнее.
7.4.2 Оценка человеком
Рисунок 7: оценка человеком, сравнивающая креативность результатов, полученных двумя методами. Эта модель стабильно превосходит базовую.
Для количественной оценки качества результатов, полученных двумя методами, была проведена оценка восемью испытуемыми. Участникам показали изображения пар (по 3 от каждой методики) и попросили определить, какое из них кажется им более креативным. Как показано на рисунке 7, явное большинство участников из всех категорий предпочли этот метод. Например, 70,8 % участников, работавших с изображениями инопланетян, и 75 % участников, работавших с транспортными средствами, выбрали этот метод. Эти результаты показывают, что метод неизменно даёт более креативный, оригинальный и привлекательный результат.
7.5 Исследования абляции
Будут проведены обширные эксперименты, чтобы более чётко продемонстрировать эффективность каждого элемента. Ниже описаны детали каждого исследования по абляции. Исследование по абляции — это эксперимент, в ходе которого удаляется часть метода, чтобы оценить, насколько хорошо работает элемент.
7.5.1 Отмените оптимизацию прямого встраивания изображений (оптимизация прямого встраивания изображений не подходит)
Рисунок 8: сравнение стратегий оптимизации. Как только вы оптимизируете e (левая колонка), результат ухудшается. Оптимизация тематических токенов (центральная колонка) и оптимизация LoRa (правая колонка) дают креативные и разумные результаты.
Чтобы изучить роль оптимизации токенов/LoRa в этом методе, мы сравниваем три стратегии, которые учитывают креативные потери: (1) прямая оптимизация встраивания изображений, (2) оптимизация встраивания слов, (3) оптимизация параметров LoRa для предварительного распределения diffusion.
На рисунке 8 показано, как меняется изображение в течение 200 итераций при каждом подходе. Прямая оптимизация параметра e (левая колонка) показывает, что качество изображения быстро ухудшается, и оно легко превращается в изображение низкого качества из‑за отсутствия ограничений по качеству. Напротив, оптимизация маркера объекта (центральная колонка) и параметра LoRa (правая колонка) приводит к творческим, но последовательным преобразованиям. Оптимизация LoRa, в частности, хорошо подходит для добавления сложных архитектурных деталей и вариаций, поскольку позволяет исследовать более широкое пространство параметров. Это будет рассмотрено более подробно в следующем разделе.
7.5.2 Тематический токен и его сравнение с прилагательным токеном и LoRa (предметный токен против лексемы прилагательного против LoRa)
Чтобы лучше понять роль концептуального пространства, мы рассмотрим несколько вариантов творческой оптимизации: (1) оптимизируйте лексему подлежащего; (2) оптимизируйте лексему прилагательного — фотореалистичный, 4k, штаб‑квартира; (3) оптимизируйте LoRa.
На рисунке 9 показаны результаты каждого подхода для домашних животных (pets) и сумок (handbags). Оптимизация тематических маркеров не является оптимальной для сумок и вызывает трудности у домашних животных — либо искажает личность субъекта, либо не проявляет креативности. С другой стороны, оптимизация лексем‑прилагательных (например, «креативный») неизменно приводит к повышению креативности. Однако эта стратегия имеет тенденцию объединять «яркий» и «красочный» в качестве средства эффективного отклонения от дистрибуции, что может ограничить разнообразие. Для сравнения: оптимизация параметров LoRa приводит к более широкому творческому преобразованию, которое не зависит только от изменения цвета. Тонкая настройка LoRa, в частности, позволяет нам выявлять больше структурных и стилистических изменений, сохраняя при этом индивидуальность основного предмета. В целом эти результаты подчёркивают преимущества изучения различных пространств параметров для творчества. Тематические маркеры, маркеры прилагательных и LoRa предлагают различные компромиссы между визуальным разнообразием, семантической точностью и простотой оптимизации.
Рисунок 9: сравнение трёх концептуальных пространств. Например, покажите 3 теста с разными исходными данными для обучения. Оптимизация тематических жетонов, особенно для домашних животных, может не привести к творческому результату. С другой стороны, оптимизация жетонов прилагательных неизменно приводит к созданию более креативного образа. Тонкая настройка LoRa, особенно в отношении сумочек, открывает более разнообразные творческие возможности, но требует больше вычислительных ресурсов.
7.5.3 Направленность
Как упоминалось в разделе 5.4, мы помечаем визуально непривлекательные регионы как отрицательные кластеры и корректируем оптимизированное распределение, чтобы оно соответствовало им и заставляло искать в другом направлении. На рисунке 10 показан этот процесс для задачи создания креативных сумочек (handbags). Первоначально модель пытается снизить вероятность, изменяя фон нежелательным образом. Как только это обнаружено, из этих вложений извлекаются негативные кластеры — это позволяет модели избегать этого направления. Затем система пытается применить второй подход, но создаёт нежелательный эстетический стиль. Таким образом, это тоже негативный кластер. В конечном итоге модель приобретает более привлекательный новый стиль, проявляя креативность благодаря новым формам и цветовым решениям. Этот результат подчёркивает важность управления направлением для обеспечения того, чтобы вероятностный поиск хвоста по‑прежнему соответствовал предпочтениям пользователя.
Рисунок 10: управление направлением для креативной сумки. Изначально модель снижает вероятность получения визуально непривлекательного результата. Помечая их как отрицательные кластеры, мы переключаем модель на другой вариант (e проецируется в 2D только для визуализации).
7.5.4 Механизм отката
На рисунке 11 показано решающее влияние двух элементов отката — потери привязки и проверки семантической достоверности (MLLM). При создании креативных результатов полная версия этого метода (верхняя часть) обеспечивает баланс креативности и семантической точности. При устранении потери привязки (средняя стадия) изображение постепенно перемещается из области синего прямоугольника за её пределы. Удаление флажка MLLM (внизу) превращает основной объект в фигуру человека, добавляя к изображению небольшой фруктовый мотив и создавая видимость соответствия изображению «фрукты». Если бы существовала семантическая проверка, она была бы обрезана в точке, указанной в зелёной рамке. Это подчёркивает уязвимость ограничений, основанных на клипах, к атакам противника (вводам, которые обманывают систему), и подтверждает необходимость обоих механизмов отката для поддержания креативности в предметной области.
Рисунок 11: Устранение механизма противодействия творческим плодам.
- Обсуждение (Discussion)
Новшество. Насколько нам известно, это первый вероятностный фреймворк для творчества в области создания текста в изображения. Мы принципиально отличаемся от ConceptLab и не полагаемся на исключение известных подклассов для создания креативного продукта. ConceptLab работает так: сначала просматривает промежуточные представления подкатегорий, а затем исключает их. Но такой подход может быть неэффективен для предметов, у которых нет чётких подклассов (например, стулья, инопланетяне), и для предметов, у которых подклассы чётко определены. Приближая модель к пределу вероятности и не опираясь на какую‑либо структуру подклассов, метод позволяет гораздо эффективнее использовать креативность.
Пределы расширения и т. д. Мы выбрали Kandinsky для демонстрации, потому что его облегчённая модель предварительного распределения позволяет быстро выполнить предварительную выборку на первом этапе. Однако этот метод также можно применить к другим платформам, например к Hyper-SD. Для удобства работы схема модели, результаты, оценка и ограничения приведены в приложении.
- Заключение
В этом исследовании мы представляем принципиальный подход к стимулированию креативности в моделях преобразования текста в изображение, явно ориентируясь на конечную точку распределения вероятности встраивания сгенерированного изображения. В дополнение к концепции скрытой диффузии для приведения модели к новому и семантически обоснованному результату были введены креативные потери, механизм отката и управление направлением. Благодаря всесторонним экспериментам и исследованиям абляции была продемонстрирована эффективность этого метода. Мы считаем, что это исследование откроет новое направление для компьютерного творчества и станет важным первым шагом на пути к созданию более выразительной, гибкой и креативной системы искусственного интеллекта.
Дополнительный материал (Supplementary Material)
S1. Дополнительные визуальные доказательства.
На рисунке 12 показан пример того, как распределение изменяется с течением времени. Это также подтверждает эффективность данного подхода, предоставляя больше наглядных доказательств — в том числе дополнительные качественные результаты по различным предметам, визуализацию оптимизированных распределений и дальнейшее сравнение с базовыми методами. Они перечислены в конце приложения.
Рисунок 12: Изменение распределения в первых 800 итерациях эксперимента «Чужой». Зелёный кластер — это предварительное распределение, а красный кластер — оптимизированное распределение во время творческой настройки. Этот метод эффективно сокращает распространение и позволяет нам искать редкие и приемлемые новые проекты.
Рисунок 13: Расширение этого метода до стабильной диффузии.
Рисунок 14: Результаты креативного использования Hyper-SD. Креативная генерация зданий с четырьмя различными исходными данными.
Подробности реализации S2.
Параметр PCA S2.1.
Исходя из этих соображений, для задачи создания креативной среды было применено сокращение с помощью PCA, при этом выбран параметр 50.
Эмпирически доказано, что уменьшение размера встраивания изображений с 768 до 50 позволяет сохранить более 95 % различий и при этом сохранить большую часть важной информации.
Несмотря на компактность уменьшенного 50‑мерного пространства, оно достаточно богато для эффективного изучения творческих вариаций и позволяет сконцентрировать процесс оптимизации на значимых различиях во встроенном пространстве.
Сокращение снижает сложность вычислений и уровень шума, делает оценку плотности более стабильной и повышает эффективность гауссовской аппроксимации в этой задаче.
PCA упрощает многомерное встроенное пространство — благодаря этому области с низкой вероятностью можно идентифицировать эффективнее, при этом удаляются избыточные и малоинформативные компоненты.
S2.2 Оценка вероятности с использованием гауссовой аппроксимации (Оценка вероятности с помощью гауссовой аппроксимации)
Решение о том, что гауссовское распределение соответствует встроенному изображению, выбранному из предварительного распределения diffusion, поддерживается несколькими факторами, которые имеют существенное значение для структуры модели diffusion.
Естественный характер гауссовского распределения: модель diffusion по сути зависит от постепенного добавления и удаления гауссовского шума. В результате промежуточное встраивание изображений, которое генерируется диффузионным предварительным распределением, склонно демонстрировать гауссовское поведение — в частности, это наблюдалось в Kandinsky 2.1. Поэтому многомерное гауссовское распределение — естественный выбор для моделирования базового распределения.
Вычислительная эффективность и простота: использование гауссовского распределения вычислительно эффективно и даёт замкнутое решение для оценки плотности. Благодаря простоте можно напрямую вычислить логарифмическое правдоподобие, а это критически важно для нашей творческой потери.
Достаточная аппроксимация для творческого поиска: задача состоит в том, чтобы привести модель к области с низкой вероятностью. Эмпирически гауссова модель даёт надёжную аппроксимацию встроенного пространства диффузионного предварительного распределения — это позволяет эффективно выявлять и исследовать конечные области, где, вероятно, появятся новые творческие результаты.
Альтернативная оценка плотности с помощью KDE. В качестве альтернативного метода моделирования распределения встраиваемых изображений также рассматривалась оценка плотности с помощью ядра (kernel density estimation, KDE). Хотя KDE даёт гибкую непараметрическую оценку плотности, чтобы обеспечить надёжную работу, нужно уменьшить размеры PCA до гораздо меньшего значения. Такое сильное уменьшение размеров привело бы к существенному рассредоточению встроенного пространства и могло ограничить разнообразие и возможности творческого поиска. Поэтому мы выбрали гауссову аппроксимацию — она обеспечивает баланс между эффективностью вычислений и выразительностью и поддерживает достаточное творческое разнообразие.
S2.3 Влияние начального уровня обучения (Эффекты начального уровня обучения)
Выбор начального уровня обучения в значительной степени влияет на творческую траекторию модели. Различные исходные данные приводят к разным путям инициализации и выборки, что позволяет использовать модель в разных областях встроенного пространства. Такая вариативность означает, что при небольшом изменении исходных данных можно получить совершенно новую группу креативных образцов. Однако также естественно, что некоторые исходные данные дают нежелательные или выходящие за рамки области результаты (см. исходное значение 4 на рисунке 5) — это отражает непредсказуемость, присущую творческому процессу. Это наблюдение ещё раз оправдывает использование мер контроля размеров — например, избегание отрицательных кластеров, — чтобы предотвратить нежелательные результаты в модели и сохранить семантическую согласованность.
S2.4. Потеря привязки (потеря привязки).
Важная проблема состоит в том, что градиентная величина потери креативности и потери привязки сильно различается. Творческая потеря даёт очень большой градиент и быстро доводит распределение до предела, тогда как потеря привязки приводит лишь к гораздо меньшему градиенту и требует множества шагов оптимизации для достижения эффекта. Градиентное ограничение может уменьшить этот дисбаланс, но полностью устранить его нельзя, а найти фиксированный коэффициент повторного взвешивания трудно — оптимальный вес может меняться в зависимости от эксперимента и испытуемого. Чтобы решить эту проблему, мы применим динамическую стратегию.
На каждой итерации производится выборка исходного материала для создания встраиваемого изображения и вычисляются как потери в креативе, так и потери в привязке.
Если потеря привязки ниже заданного порога, общая потеря устанавливается равной потере в креативе, и на следующей итерации производится выборка нового исходного материала.
И наоборот, если потеря привязки превышает пороговое значение, установите для общей потери значение потери привязки и продолжайте оптимизацию с тем же начальным значением, пока образец не удастся извлечь обратно.
Такой подход позволяет нам непрерывно оптимизировать одну и ту же выборку до тех пор, пока она не будет безопасно восстановлена в пределах допустимого диапазона, — это уравновешивает эффект атаки на творческую потерю со стабилизирующим эффектом восстановления потери привязки.
Расширение S3 для других фреймворков (расширение для других фреймворков).
Метод основан на вероятностном подходе к созданию креативных изображений и может быть распространён на фреймворки, отличные от Kandinsky. На рисунке 13 показано расширение Hyper-SD — метод дистилляции стабильной диффузии. Результат создания креативного здания показан на рисунке 14.
S4. Масштабные визуальные результаты (масштабные визуальные результаты).
Здесь показано большое количество визуальных результатов (смотрите следующую страницу и далее).
Рисунок 15–20: сравнение случайной выборки с исходным уровнем для зданий, сумок, инопланетян, транспортных средств, домашних животных, фруктов.
Рисунок 21–25: примеры креативной генерации в приложении (сумка, здание, стул, домашнее животное, динозавр, инопланетянин — оба LoRa).
Раздел 4.1. Оценка человеком (оценка человеком).
Мы провели масштабные опросы по оценке персонала на Amazon Mechanical Turk и на исследовательской платформе WJX, собрав более 600 индивидуальных оценок от более чем 6000 пользователей. Эта масштабная оценка даёт надёжную количественную оценку креативности и семантической точности генерируемых результатов. Пример исследования показан на рисунке 26.
Исходный текст — Лицензия.
Оригинальное название: Креативная генерация изображений с использованием диффузионных моделей.
Автор: Кунпенг Сонг, Ахмед Эльгаммал (Университет Рутгерса).
Источник: arXiv: 2601.22125 — https://arxiv.org/abs/2601.22125
Страница проекта: https://creative-t2i.github.io/
Лицензия: CC BY 4.0 (Creative Commons Attribution 4.0 International) — https://creativecommons.org/licenses/by/4.0/
Эта статья — японский перевод вышеупомянутой статьи (CC BY 4.0). Она принадлежит автору оригинала. Если вы хотите изменить язык перевода, вы можете сделать это, сменив язык. Номера формул и рисунков соответствуют оригинальному тексту. Пожалуйста, ознакомьтесь с оригиналом (arXiv) самого рисунка.
Предложите отредактировать в обсуждении на GitHub

